Vodič za HBase: Uvod o HBase i Facebook studija slučaja
Ovaj HBase tutorial blog upoznaje vas s HBase-om i njezinim značajkama. Također obuhvaća studiju slučaja Facebook Messenger kako bi se razumjele prednosti HBase-a.

Ovaj HBase tutorial blog upoznaje vas s HBase-om i njezinim značajkama. Također obuhvaća studiju slučaja Facebook Messenger kako bi se razumjele prednosti HBase-a.
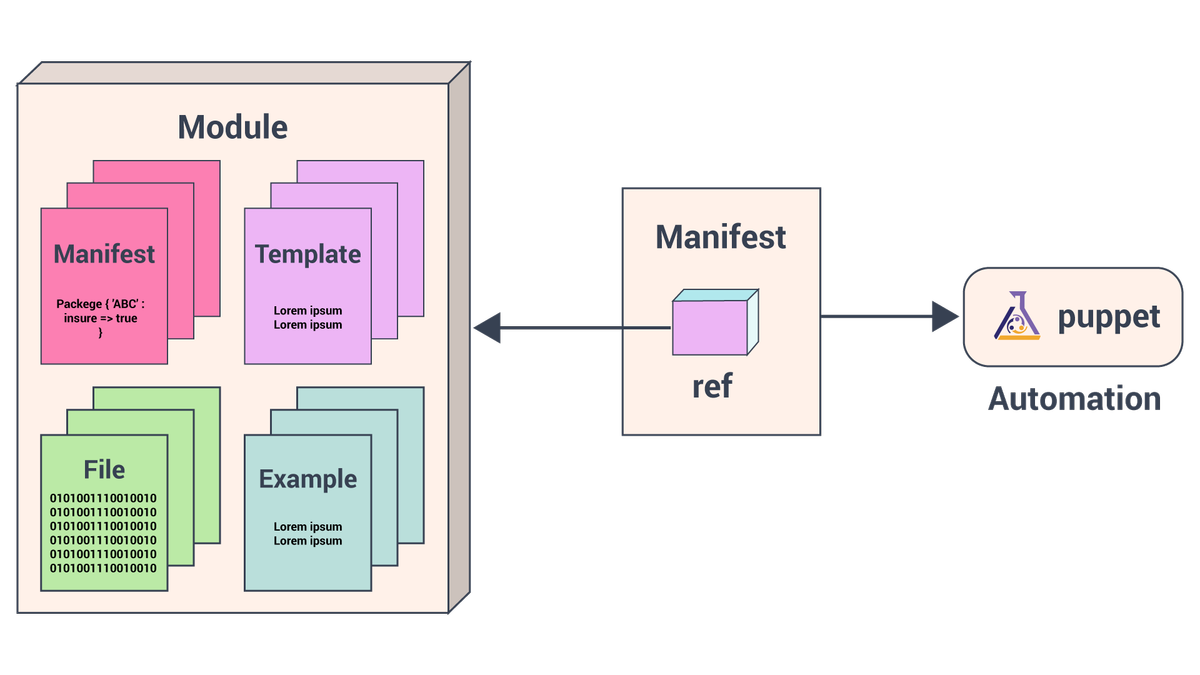
Ovaj je blog vodič o tome kako instalirati Puppet Master i Puppet Agent. Također uključuje primjer raspoređivanja Apache Tomcat pomoću modula Puppet Tomcat.
Ovaj je blog korak po korak vodič za instalaciju Apache Pig u Linux okruženju. Instalirat ćemo Apache Pig 0.16.0 i pokretati ga u različitim načinima.
Ovaj blog o HBase arhitekturi objašnjava HBase model podataka i daje uvid u HBase arhitekturu. Također objašnjava različite mehanizme u HBase.
Ovaj tutorial blog Hive daje vam detaljno znanje o arhitekturi košnica i modelu podataka o košnici. Također objašnjava NASA-inu studiju slučaja Apache Hive.
Ovaj blog Spark Streaming upoznat će vas sa Spark Streamingom, njegovim značajkama i komponentama. Uključuje projekt Analize raspoloženja pomoću Twittera.
Ovaj blog Spark MLlib upoznat će vas s bibliotekom strojnog učenja tvrtke Apache Spark. Uključuje projekt sustava za preporuku filmova koji koristi Spark MLlib.
Ovaj blog s vodičem za GraphX upoznat će vas s Apache Spark GraphX-om, njegovim značajkama i komponentama, uključujući projekt analize podataka o letu.
Ovaj tutorial blog Apache Flume objašnjava osnove Apache Flumea i njegove značajke. Također će prikazati streaming na Twitteru koristeći Apache Flume.
Vodič za Apache Sqoop: Sqoop je alat za prijenos podataka između Hadoop-a i relacijskih baza podataka. Ovaj blog pokriva Sooop uvoz i izvoz iz MySQL-a.
Vodič za Apache Oozie: Oozie je sustav za planiranje tijeka posla za upravljanje Hadoop poslovima. To je skalabilan, pouzdan i proširiv sustav.
Aplikacije velikih podataka revolucioniraju organizacije i pomažu im u donošenju informativnijih poslovnih odluka analizom velike količine podataka.
Apache Spark preuzeo je svijet velikih podataka i analitike, a Python je jedan od najpristupačnijih programskih jezika koji se danas koristi u industriji. Dakle, ovdje na ovom blogu naučit ćemo o Pysparku (iskra s pythonom) kako bismo izvukli najbolje iz oba svijeta.
Ovaj se blog fokusira na Apache Hadoop YARN koja je uvedena u Hadoop verziji 2.0 za upravljanje resursima i raspoređivanje poslova. Objašnjava YARN arhitekturu sa svojim komponentama i zadaćama koje obavlja svaki od njih. Opisuje predaju prijave i tijek rada u Apache Hadoop YARN.
Na ovom blogu na vodiču za PySpark naučit ćete o API-ju PSpark koji se koristi za rad s Apache Spark-om koristeći programski jezik Python.
U ovom blogu tutorijala za PySpark Dataframe naučit ćete o transformacijama i radnjama u Apache Sparku s više primjera.
Ovaj Edureka blog na Cloudera Hadoop Tutorial pružit će vam cjelovit uvid u različite komponente Cloudere kao što su Cloudera Manager, Parcels, Hue itd.
Ovaj post opisuje porast potražnje za Hadoop i NoSQL vještinama u IT-u i drugim poljima. čitajte kako biste vidjeli kako će vam pomoći vještine Hadoop i NoSQL
Ovaj blog raspravlja o prednostima implementacije Hadoopa, Hadoop inicijativama, Hadoop-u u malim i velikim organizacijama i prednostima Hadoop treninga u karijeri.
Hadoop je postao vruća vještina koja se stječe u IT krugu, a broj profila učenika u Hadoopu drastično se povećava iz dana u dan.